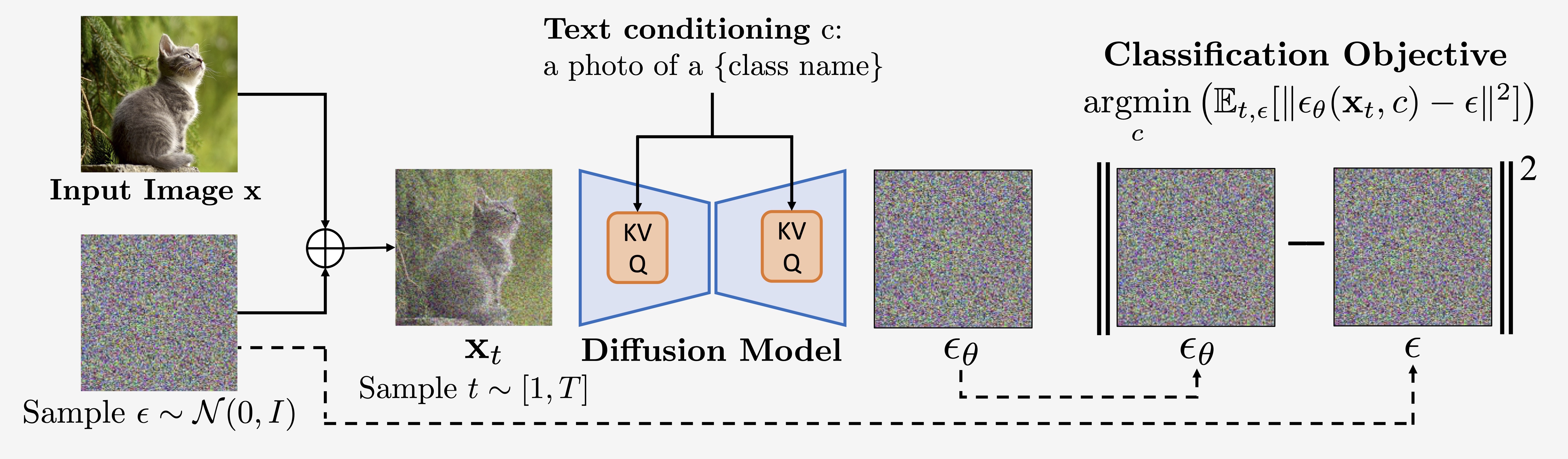
In general, classification using a conditional generative model can be done by using Bayes'
theorem on the model predictions and the prior \(p(\mathbf{c})\) over labels
\(\{\mathbf{c}_i\}\):
\begin{equation}
p_\theta(\mathbf{c}_i \mid \mathbf{x}) = \frac{p(\mathbf{c}_i)\ p_\theta(\mathbf{x} \mid
\mathbf{c}_i)}{\sum_j p(\mathbf{c}_j)\ p_\theta(\mathbf{x} \mid \mathbf{c}_j)}
\label{eq:bayes}
\end{equation}
A uniform prior over \(\{\mathbf{c}_i\}\) (i.e., \(p(\mathbf{c}_i) = \frac{1}{N}\))
is natural and leads to all of the \(p(\mathbf{c})\) terms cancelling. For diffusion models,
computing \(\log p_\theta(\mathbf{x}\mid \mathbf{c})\) is intractable, so we approximate it
with the ELBO (see paper §3.1), from which we have dropped constant and weighting terms:
\begin{align}
\text{ELBO} \approx - \mathbb{E}_{t, \epsilon}[\|\epsilon - \epsilon_\theta(\mathbf{x}_t,
\mathbf{c}_i)\|^2]
\label{eq:elbo}
\end{align}
We plug the modified ELBO Eq. \ref{eq:elbo} into Eq. \ref{eq:bayes} to obtain the
posterior over
\(\{\mathbf{c}_i\}_{i=1}^N\):
\begin{align}
p_\theta(\mathbf{c}_i \mid \mathbf{x})
&\approx \frac{\exp\{- \mathbb{E}_{t, \epsilon}[\|\epsilon - \epsilon_\theta(\mathbf{x}_t,
\mathbf{c}_i)\|^2]\}}{\sum_j \exp\{- \mathbb{E}_{t, \epsilon}[\|\epsilon -
\epsilon_\theta(\mathbf{x}_t, \mathbf{c}_j)\|^2]\}}
\label{eq:posterior}
\end{align}
We compute an unbiased Monte Carlo estimate of each expectation by sampling \(N\) \((t_i,
\epsilon_i)\) pairs, with \(t_i \sim [1, 1000]\) and \(\epsilon \sim \mathcal{N}(0, I)\),
and computing
\begin{align}
\frac{1}{N}\sum_{i=1}^N \left\|\epsilon_i - \epsilon_\theta(\sqrt{\bar
\alpha_{t_i}}\mathbf{x} + \sqrt{1-\bar\alpha_{t_i}} \epsilon_i, \mathbf{c}_j)\right\|^2
\label{eq:monte_carlo}
\end{align}
By plugging Eq. \ref{eq:monte_carlo} into Eq. \ref{eq:posterior}, we can extract a
classifier from any conditional diffusion model.
This method, which we call Diffusion Classifier, is a
powerful, hyperparameter-free approach that leverages pretrained diffusion models for
classification without any additional training.
Diffusion Classifier can be used to extract a zero-shot
classifier from a text-to-image model like Stable Diffusion, to extract
a standard
classifier from a class-conditional diffusion model like DiT, and so on.